网易伏羲:让生成式AI与中国用户心有灵犀(网易伏羲机器人)
作者:来源网络 来源:网络 时间:2023-04-01 05:23:00
前言
从临近中国的兔年开始,生成式AI(又称AIGC)的发展可谓“兔”飞猛进。几乎每周都有许多新的消息和成果发布,更低的门槛和更好的效果不断冲击大众认知,让越来越多的人认知到生成式AI已经成为推进下一轮技术革新的重要动力。同时,也有越来越多的人开始思考一些问题,比如:为什么最好的生成效果不在中国?中国的生成式AI离国外有多远?要做出最好的生成式AI,除了模型,我们还需要建设哪些东西?
网易伏羲作为国内首个专注数字文娱领域的人工智能研究机构,从17年成立之初开始关注生成式AI的发展和落地可能,这些问题在过去的几年内不断在团队内部被提及、讨论,并驱动一系列工作的开展和推进。本文将介绍网易伏羲对这些问题的思考,以及当前的一些进展。
自然语言与生成式AI
这一轮生成式AI的爆发,需要从自然语言处理技术的突破说起,17年谷歌提出Transformer架构,使得计算机可以更加高效地进行文本内容知识的学习,从而推动BERT、GPT等一些列大规模文本模型的诞生,从理解和生成的维度都获得了巨大突破。而自然语言处理这门连接人类和计算机交流的基础学科,也成为驱动包括文本、图像、音频、视频、三维模型等各个维度生成式AI爆发的核心基座。一方面人们从海量的互联网数据当中整理可以用于生成式AI训练的数据,另外一方面通过自然语言来对齐各个模态的信息,使得这些知识可以互通。这也可以很好的解释为什么英文生态的公司和机构在这一轮技术热潮中更容易占据先机 -- 当前规模最大、内容最丰富、质量最高的机器学习语料是由英文构成的。
例如文本下游微调数据,英文领域有像T0-SF,Muffin等大量优质的数据集,图文领域也有像LAION-2B,MSCOCO等开源数据集。相比于国内,中文领域虽然这两年也有多个相关数据集的建设,如200G悟道文本预训练数据集,“悟空”1亿图文对数据集等,但是无论从数量还是质量上来比,与海外的数据还是存在着一定的差距。
除此之外,英文生态本身也具备非常明确的先天优势,其包含了大量其他语种不具备的优质的内容。比如说全球最顶尖的学术论文、编程代码、多个行业领域的规范标准。这些构成了英文的独天得天独厚的优势,也使得基于英文生态的研究方案可以更好的去推动和落地。
如何走出数据困境
面对这样的数据困境,国内的研究者和机构又采取了哪些办法?归结来看大概有4种策略:
1、直接用开源模型,走API翻译
这可能是最直接的方案,尤其在图文生成领域,去年stable diffusion模型开源之后国内有不少创业公司尝试直接基于该模型进行适配训练和推理生成,同时利用 API的翻译接口将中文的输入转化成英文实现对中文用户的支持。这条路线的好处是可以快速地将最新的英文生态的工作应用到国内。缺点也非常明显,一方面是中文翻译可能引起语义的缺失,很多英文这个领域当中常用的说法在中文当中是没有办法很好的表达的,比如说中国的许多成语以及谚语:

飞流直下三千尺 from Mid Journel

竹杖芒鞋轻胜马 from Mid Journel
海外数据的内容组成也大多由当地的人文地理,生活历史构成,对于中文的知识缺乏很好的理解,比如说中国的历史古迹、名人、美食和生活习俗。

西湖断桥 from midjournel

过桥米线 from mid journel
第三点也是最核心的一点:已有开源模型数的数据据存在偏见,合规性和安全性都留有风险。举例说,这些模型在种族问题上不平等,也存在大量裸露、暴力的内容。直接将这些数据模型用于国内的生产,存在着巨大的隐患,所以从年初开始,相关部门对生成式AI的能力构成加大了审核力度。
2、海外数据翻译
这种方案是第一种方案的改进版。具备一定研究能力的机构,会选择将海外数据整理下来之后进行英文到中文的翻译,借助英文数据已有的成果,构建更加可靠的自有模型,目前国内有不少研究机构和企业采取了这条路线。优点是可以继承英文的丰富的数据生态,同时可以对涉黄、涉政的数据进行系统性筛选。
缺点还是存在领域差异,包括对一些特定的中文表述、生态、文化习俗的缺失,以及数据本身还是带有非常强的偏见,甚至是歧视。即使去除了不合规的数据,这些隐性的问题还是很难解决的。比如“穿旗袍的女孩”,“七夕节日”等等。
3、中文数据构建
这是一条相对难走的道路,需要大量前期的积累。数据的整理的工作往往在短期内难以获得成效,其阶段性价值也难以衡量。但完善的高质量数据的建设,将对生成式AI后期的工作推进带来可靠的助力。所以在伏羲以往的讨论当中,这也被认定为是一条难走却又正确的道路。自建中文数据集的好处在于可以解决中文场景的一系列基础性问题,弥补模型对中文知识的欠缺,更好的去控制数据安全,从而对数据的合规性进行有效审核。
国内目前也有一些做了中文数据构建的这些工作,高质量对齐数量例如coco-cn,数据量级别在十万级别,数据量较少。wukong数据集是目前较大规模的开源图文数据集,但相比海外的对标数据集目前还是存在一定差距。许多场景之下,相关的研究人员也开始呼吁国内的政府和企业可以推进高质量的中文数据集的共建,我们也看到有许多国内同行开始加入到这个行列。
4、多语言兼容
自建数据集虽好,但依然无法解决其他语言优质内容缺乏的问题。所以多语言兼容是目前看起来大规模预训练模型技术比较切实可行的方案。当然,这个方案目前依旧在验证当中,当前已经有一些相关的工作,通过多语言的方案,将英文场景下图文理解,文图生成功能,扩展到其他的语种中,打通了英文体系和其他语种的障碍。
在ChatGPT的训练过程当中,已经体现展现出跨语言的可行性以及潜力。由于有大量的多元数据融合,目前GPT的中文能力已经比许多纯中文预训练模型更加出色。在图文生成领域,Niji模型的跨语言能力和生成效果都是不错的。
伏羲的破境之举
从生成式AI的整体效果考虑,伏羲选择了一条比较长期的技术路线。在兼容开源数据的同时,又分为4步推进,首先是建设高质量的大规模中文数据集;其次构建中文领域的优质理解模型;然后基于数据集和理解模型重构图文生成算法,做到语义的有效提升;最后引入专家和人类的反馈引导模型生成用户更加需要的高质量内容。
1、建设大规模中文数据
伏羲联合网易多个部门,包括网易雷火、传媒、云音乐等核心业务,从用户和业务维度提供对数据的理解和需求,完成对于优质数据的定义,建设包括文本质量,图像美观度,版权合规性以及伦理评估等评价标准。以此框架作为约束共同推进数据构建,同时设计了一套基于分布式任务的数据可信系统,各专家团队各自提供数据质量评审模型,完成共同打分后再交由数据治理引擎统一管理。
2、构建中文领域的理解模型
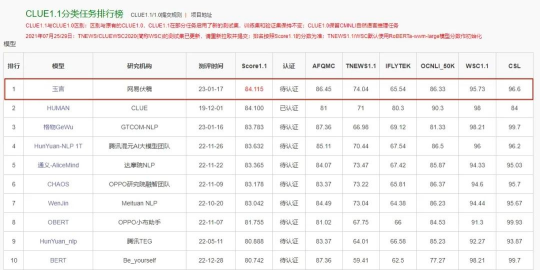
基于伏羲自研千亿文本模型的技术积累,“玉言”系列理解模型先后登顶知名中文榜单FewCLUE和CLUE分类榜单,在CLUE1.1分类任务排行榜(包含AFQMC[文本相似度]、TNEWS[短文本分类]、IFLYTEK[长文本分类]、OCNLI[自然语言推理]、WSC[代词消歧]、CSL[关键词识别]6个理解任务)上超过人类水平。玉言系列中的百亿生成模型与对话模型已完成开源,理解模型也会在近期开源。
在文本理解的基础之上,伏羲自2021年起着力打造“玉知”多模态图文理解大模型,采用图片-文本双塔结构和模块化的训练思想,基于亿级别的中文图文数据对,先后迭代了三种规格的模型版本,在中文图文理解水平上达到业界领先水平,并具有良好的泛化性,在下游各类任务如分类,检索,推荐等方面表现优异;并且,在图文模型的预训练过程中,针对包含不同文本长度的图文对采用不同的训练策略,这使得“玉知”模型对语义具有较强的理解能力。同时,利用网易伏羲开源的EET高效推理框架,对模型压缩、算法适配、硬件底层等方面进行优化,使其推理速度提升4倍,满足了线上的高并发需求,降低了部署资源的损耗。
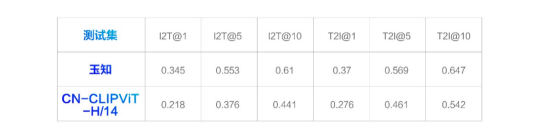
在业务数据集的zero-shot评测中
“玉知”多模态理解大模型优于Chinese-CLIP的CN-CLIPViT-H/14
玉知模型也成功在网易的多个业务中得到验证,如网易新闻和网易云音乐的搜索、推荐、智能标注等场景。网易新闻通过图文大模型构建的图文内容表征,在推荐环节采用基于该图文向量的dropoutnet召回优化,对召回源、列表页视频试投、列表页试投整体等效果明显改进,实现视频和整体大盘的业务指标提升,已在线上业务中落地使用。网易云音乐通过图文大模型构建的内容表征引擎和内容相似检索引擎,已成功应用于云音乐视频、长音频、广告等多个内容业务,对内容冷启动效率、CTR预估模型等,带来显著的线上收益。同时进一步联合华为团队,充分分析互联网行业数据集特性,对多模态模型结构进行优化,优选合适编码器并采用多阶段训练模式,共建玉知-悟空模型,进一步构建伏羲在中文跨模态理解领域的领先优势。
3、图文生成算法重构
在图文理解预训练模型的基础上,伏羲进一步推进自研文图生成模型——“丹青”的研发,一种语义增强的文图生成扩散模型。依托于扩散模型的原理,在广泛的(8亿)图文数据上训练以达到较好的生成结果。不同于常见的基于扩散模型的文图生成方法,伏羲自研的模型还具备以下特点:
1. 模型创新:文图生成的语义能力,非常强依赖对用户输入文本的表征能力,依托于伏羲自研的”玉知”模型在中文语境下的表征能力,自研生成模型在中文场景下具有的超强语义表征能力。此外,伏羲自研模型还侧重文本与图片交互的,强化了在文图引导部分的参数作用,能够让文本更好地引导图片的生成,因此生成的结果也更加贴近用户意图。
2. 图片多尺度的训练:在广泛的数据集中,自研模型在充分考虑图片的不同尺寸和清晰度问题,将不同尺寸和分辨率的图片进行分桶,从而进行的多尺度训练。在充分保证训练图片训练的不失真的前提下,保留尽可能多的信息,自研模型能够适应不同分辨率的生成。
3. 数据策略:多阶段的训练能够保证模型既具有广泛性,又保证生成结果的质量。初始阶段,使用亿级别的广泛分布的数据,让模型不仅在语义理解上具有广泛性,可以很好的理解一些成语,古文诗句,例如夫妻肺片,名花倾国等等。同时在生成的画风上也具有多样性,可以生成多种风格。在之后的阶段分别从图文关联度,图片清晰度,图片美观度等多个层面进行数据筛选,以优化生成能力,生成高质量图片。
l 中文场景下超强的语义理解能力: 能够充分理解用户的输入,并且返回给用户想要的东西。尤其在成语,俗语,诗句的理解和生成具备一定优势。

l 风格的多样性 & 纯正性 :覆盖的风格广泛,例如年轻人热爱的二次元,动漫风格,传统的山水国画风格,以及知名画家的特殊风格等。




l 中文场景的领域优势:善于生成中国元素的作品,例如宋代美女,传统佳节等场景





4、人机协同增强的数据闭环
依赖于机器进行数据筛选,不可避免存在诸多缺陷和不完美。依托于网易伏羲的aop众包能力,我们从不同角度引入了人工。在训练阶段,人工从多个维度的评估,筛选出来大批高质量图文匹配、高美观度数据,以补足自动流程缺失能力,帮助基础模型获得更好的效果。同时,我们在模型的生成阶段,也引入人工的反馈,对模型的语义生成能力和图片美观度进行评分,筛选出大批量优质生成的结果,引入模型当做正反馈,实现数据闭环。更好提升了模型的理解能力和生成能力。
后续工作与展望
以上四个维度的建设,使得网易伏羲的图文生成式AI具备较好的中文理解及美观度表达能力,在做到与中国用户“心有灵犀”的工作道路上迈出了第一步。生成式AI技术革新的序幕刚刚开始拉起,随着生产力的不断释放和新的开源生态建立,在联通算法、数据、算力和人的工作上还有很多事情要做。除了持续优化生成效果,对于AI在将来工作流当中的价值、已有知识产权的保护、AI伦理的规范遵守等一些问题,也需要持续的思考和完善。
目前,网易伏羲正在推进中文领域的生成式人工智能平台-“丹青约”的建设,并携手集团内部生态共同参与艺术风格和算法模型的设计和训练。为行业用户提供高效微调适配、低成本模块化推断、开源生态快速集成、生成模型定制加速等完整解决方案,为艺术家们提供更加灵活的生产力工具,寻找更新的艺术形态,为推动中文语义理解和科技创新注入新的力量。
- 上一篇: 原神3.6直播兑换码(原神3.6版本直播时间)
- 下一篇: 没有了
相关攻略
更多资讯
-
 跨界当道 | ChinaJoy跨界营销案例赏:果子熟了
跨界当道 | ChinaJoy跨界营销案例赏:果子熟了 -
 风域游戏确认参展,INDIE GAME 展区持续招商中!
风域游戏确认参展,INDIE GAME 展区持续招商中! -
 成都鬼脸科技有限公司确认参展2023ChinaJoyBTOB(成都鬼脸科技有限公司面试)
成都鬼脸科技有限公司确认参展2023ChinaJoyBTOB(成都鬼脸科技有限公司面试) -
 2023 ChinaJoy潮玩手办模型展区(CJTS&CJFM)全新升级,火热招商中!
2023 ChinaJoy潮玩手办模型展区(CJTS&CJFM)全新升级,火热招商中! -
 PUBG与你“益”起 糗糗庄园领养日6只小猫咪找到新家(你PUBG)
PUBG与你“益”起 糗糗庄园领养日6只小猫咪找到新家(你PUBG) -
 PUBG愚人节游戏模式-奇奇怪怪大乱斗正式开启(pubg愚人节98k)
PUBG愚人节游戏模式-奇奇怪怪大乱斗正式开启(pubg愚人节98k) -
 经典桌游联手宝可梦!艾赐魔袋中国宣布推出《嗒宝:宝可梦》
经典桌游联手宝可梦!艾赐魔袋中国宣布推出《嗒宝:宝可梦》 -
 《天下3》三月同人月刊闪亮登场!脑洞大开的少侠教拳打万相,横扫北溟中~(《天下3》英雄榜)
《天下3》三月同人月刊闪亮登场!脑洞大开的少侠教拳打万相,横扫北溟中~(《天下3》英雄榜) -
 最终出线名额争夺战 《坦克世界》WOC小组赛第三周赛程开启(VIT争夺A组出线名额)
最终出线名额争夺战 《坦克世界》WOC小组赛第三周赛程开启(VIT争夺A组出线名额) -
 玛法新征途《传奇归来》新归来24区“乘风破浪”火爆开启!
玛法新征途《传奇归来》新归来24区“乘风破浪”火爆开启! -
 大神APP4.1黑科技上新!“神翻译”读懂TA的真心话(大神APP下载)
大神APP4.1黑科技上新!“神翻译”读懂TA的真心话(大神APP下载) -
 2023同城玩家聚会活动入选名单出炉!出发西安(同城红包群2023)
2023同城玩家聚会活动入选名单出炉!出发西安(同城红包群2023)
热门攻略


推荐游戏
换一换


























- 人气排行
- 1梦幻公益开启新篇章!携手小动物保护协会守护流浪天使
- 2奇幻森林 第五人格植树节奇珍随从现已上线
- 3未定事件簿白色情人节专属邮件 共度纯白节日倾诉甜蜜眷恋(未定事件簿怎么白嫖密钥)
- 4明日方舟SideStory「吾导先路」复刻即将开启(明日方舟sidestory会复刻吗)
- 5稚兔映童真 乐园夺奇宝 自在西游兔兔乐园欢趣上线!
- 6世界弹射物语230抽送不停,一周年庆典福利情报合集(世界弹射物语下载)
- 7刀剑合璧力补天痕,舞乐青铜相约天赐!新版本外观、活动爆料,速戳了解
- 8崩坏3活动情报 | 全新主线第三十六章「启自长空」玩法说明
- 9《魔域》年度新资料片回顾:全职觉醒集体变强,游戏体验全面升级!
- 10创新公益模式 迷你创想荣获广东游戏产业年会“年度社会公益奖”